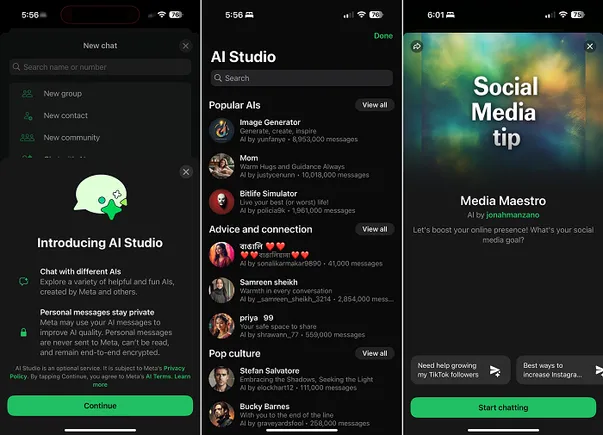
![How to Find Low-Competition Keywords with Semrush [Super Easy]](https://static.semrush.com/blog/uploads/media/73/62/7362f16fb9e460b6d58ccc09b4a048b6/how-to-find-low-competition-keywords-sm.png)







































































































































































.jpg)
%20Abstract%20Background%20112024%20SOURCE%20Amazon.jpg)










OpenAI’s models ‘memorized’ copyrighted content, new study suggests
A new study appears to lend credence to allegations that OpenAI trained at least some of its AI models on copyrighted content. OpenAI is embroiled in suits brought by authors, programmers, and other rights-holders who accuse the company of using their works — books, codebases, and so on — to develop its models without permission. […]

A new study appears to lend credence to allegations that OpenAI trained at least some of its AI models on copyrighted content. OpenAI is embroiled in suits brought by authors, programmers, and other rights-holders who accuse the company of using their works — books, codebases, and so on — to develop its models without permission. […]